

Lecture 2
MRP 马尔科夫奖励过程
\[
\begin{equation}
\left(\begin{array}{c}
V\left(s_1\right) \\
\vdots \\
V\left(s_N\right)
\end{array}\right)=\left(\begin{array}{c}
R\left(s_1\right) \\
\vdots \\
R\left(s_N\right)
\end{array}\right)+\gamma\left(\begin{array}{ccc}
P\left(s_1 \mid s_1\right) & \cdots & P\left(s_N \mid s_1\right)
\\
P\left(s_1 \mid s_2\right) & \cdots & P\left(s_N \mid s_2\right)
\\
\vdots & \ddots & \vdots \\
P\left(s_1 \mid s_N\right) & \cdots & P\left(s_N ...
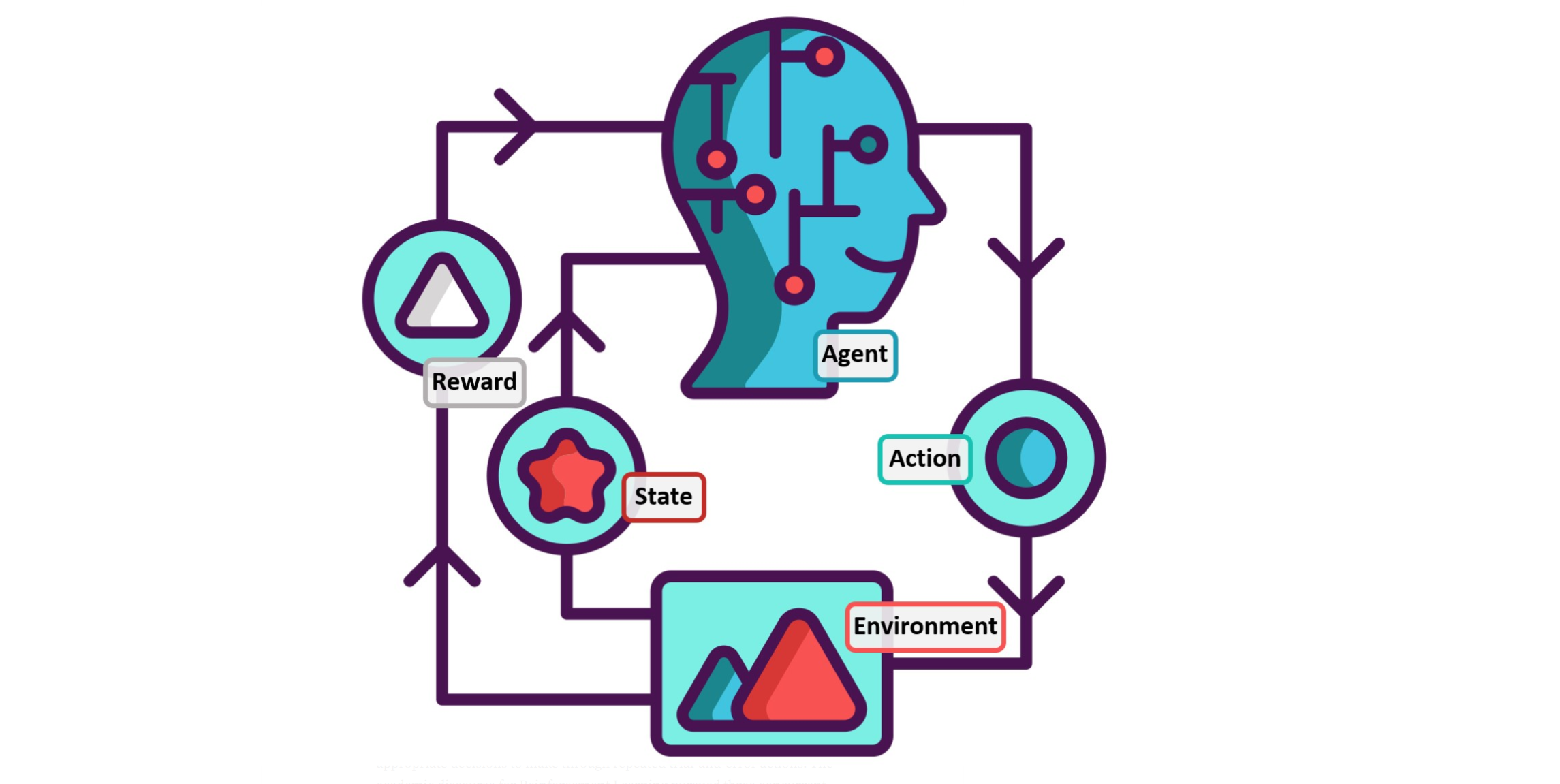
Multiarmed Bandits问题
多臂老虎机问题
多臂老虎机是假设在玩一个拥有多个摇臂的老虎机,每个摇臂对应一个动作,玩家一次只能选取一个摇臂,相当于是选取了一个动作,描述如下:
老虎机有K个摇臂,每个摇臂以一定的概率吐出金币,且概率是未知的,但服从一定的概率分布即
\[
\mathcal{R}^{a} (r) = \mathbb{P}[r|a]
\]
玩家每次(每个时间步step)只能从K个摇臂中选择其中一个摇臂 \(a \in
\mathcal{A}\),且相邻两次选择或奖励没有任何关系
环境会给出奖励
\[
r_t \sim \mathcal{R}^{a_t}
\]
玩家的目的是通过一定的策略使自己获得的累计奖励最大,即得到更多的金币
\[
\sum_{\tau=1}^t r_\tau
\]
贪心算法选取最优动作Greedy
Algorithm
使用蒙特卡洛算法估计的动作值
\[
\hat{Q}_t(a)=\frac{1}{N_t(a)} \sum_{t=1}^T r_t
\mathbb{1}\left(a_t=a\right)\\
\Rightarro ...

MADRL
Deep Reinforcement Learning for Multiagent Systems: A
Review of Challenges, Solutions, and Applications
多Agent系统的深度强化学习:挑战、解决方案和应用综述
Key
Value
文献类型
journalArticle
标题
Deep Reinforcement Learning for Multiagent
Systems: A Review of Challenges, Solutions, and Applications
中文标题
多Agent系统的深度强化学习:挑战、解决方案和应用综述
作者
[[Thanh Thi Nguyen]]、 [[Ngoc Duy
Nguyen]]、 [[Saeid Nahavandi]]
期刊名称
[[IEEE Transactions on Cybernetics]]
DOI
10.1109/TCYB.2020.2977374
引用次数
281 📊
影响因子
19.11 ...

Power method 估计复杂度
power method 的原理,其实就是利用矩阵的性质得到最大特征值的表达式
实例
Log-Barrier-method
在求一些优化问题的时候,往往遇到形式如下的问题:
\[
\begin{array}{lll}
\text { Problem statement } & h: \mathbb{R}^{n_x} \rightarrow
\mathbb{R}^{n_h} \\
\min _{x \in \mathbb{R}^{n_x}} & f(\boldsymbol{x}) &
\boldsymbol{g}: \mathbb{R}^{n_x} \rightarrow \mathbb{R}^{n_g} \\
\text { subject to: } & \boldsymbol{h}(\boldsymbol{x})=\mathbf{0}
& \\
& \boldsymbol{g}(\boldsymbol{x}) \leq \mathbf{0}
\end{array}
\]
即需要满足\(x\)在\(h(x)\) 上且 \(g(x) \leq 0\) 时最小化\(f(x)\) 的值。
采用barrier的方法可以求得此解 ...

Many-Agent Reinforcement Learning-chapter
4
多智能体强化学习-1
Key
Value
文献类型
journalArticle
标题
Many-Agent Reinforcement Learning
中文标题
多代理强化学习
作者
[Yaodong Yang]
评分
⭐⭐⭐⭐⭐
分类
[[A 多智能体增强学习, 0 综述]]
条目链接
My Library
PDF 附件
2021__Yang__Many-Agent Reinforcement
Learning.pdf
👣➿👣
Alpha rank :
Mathmatical formulation
假设有\(N\)个agent,每个agent有\(k_i\)个策略,则有
单个智能体的策略集 \(\mathscr{S}_i\) , 大小为\(k_i\): \(\mathscr{S}_i=\left\{\pi_{i, 1}, \ldots, \pi_{i,
k_i}\right\}, k_i=\left|\mathscr{ ...

Single-Agent RL
Markov process 马尔科夫过程
image-20220505143413803
马尔科夫过程是一个标准模型,广泛应用在全观测状态系统中,即智能体可以完全获取环境的状态信息,通过概率转换模型,在某一个状态通过一个动作到达另一个状态。因此结局马尔科夫问题的关键就是找到一个策略使得动作空间\(A\)映射到状态空间\(S\)上去。其中动作为\(a_{t} \sim \pi\left(\cdot \mid
s_{t}\right)\) ,并能使得到达每一个状态获取的回报discounted
accumulated reward能够被最大化:
\[
\mathbb{E}\left[\sum_{t \geq 0} \gamma^{t} R\left(s_{t}, a_{t},
s_{t+1}\right) \mid a_{t} \sim \pi\left(\cdot \mid s_{t}\right),
s_{0}\right]
\]
其中action-value function(Q方程)和state-value function
(V方程)分别为 ...
Active learning 主动学习
Active ADP
active ADP的更新公式
\[
\begin{equation}
U(s)=\max _{a \in A(s)} \sum_{s^{\prime}} P\left(s^{\prime} \mid s,
a\right)\left[R\left(s, a, s^{\prime}\right)+\gamma
U\left(s^{\prime}\right)\right]
\end{equation}
\]
active adp 和passive
adp的主要区别是在于agent在学习效用函数时,对于passive
ADP在某个状态的策略是固定的,对于active
adp在某个状态下有多个动作可以选择,active adp
会选择产生的最大的效用值作为expected utility value(MEU).
exploration and exploitation
智能体对环境的探索依然受到exploration和exploitation的限制,对于使用ADP算法,可以将乐观估计融入效用之更新公式中:
\[
\begin{ ...
Decision Trees决策树
使用Entropy计算率先分割哪个decision
tree的分支
计算一个随机变量的不确定性使用熵,如果一个硬币投掷后头面朝上的概率为1的话,那这个硬币代表的随机变量的不确定性就为0,如果一个硬币有50%的概率投掷硬币头朝上,则其熵计算为:
熵的计算公式:单位为比特
信息增益 information gain
一颗决策树中的非叶子节点有split函数,用于将当前所输入的数据分到左子树或者右子树。我们希望每一个节点的split函数的性能最大化。这里的性能是指把两种不同的数据分开的能力,不涉及到算法的时间复杂度。但是,怎么去衡量一个split函数的性能呢?这里我们使用信息增益来衡量G。如果G越大,说明该节点的split函数将输入数据分成两份的性能越好。
版权声明:本文为CSDN博主「ChainingBlocks」的原创文章 原文链接:https://blog.csdn.net/liangyihuai/article/details/103206360
如果一个decision
tree拥有不同的attribute将一个训练集分割成不同的组 ...

