


















LobeChat 服务器版本部署
今天折腾了一整天,终于把lobechat的服务器版给建立好了。
LobeChat 知识库发布
非常良心,服务器版本竟然是完全开源,没有一点隐藏,反而部署到服务器上比云版本的更好,因为储存空间就没有了限制了。
但是实际上能当成云盘还是有门槛的,我是使用了花生壳的透穿映射,所以可以有无限的流量,同时服务器的硬盘大大的,能够真的无限制上传文件到知识库。
我是使用的minio作为S3数据库来储存各种文件到本地,免费又好用,然后使用github作为auth对用户登录进行验证,唯一有点门槛的是需要用花生壳将minio的api接口映射出去,同时还需要映射lobechat的登录界面,这样就需要消耗两个端口映射,具体的部署方法可以直接看lobehub官方说明.
对于知识库这个东西,其实还是有点用的,我是没有用官方的模型作为embedding模型,因为太贵了,但是目前似乎lobechat只支持openai的embedding
模型,没办法只能使用模型商的二手,这里用的是chatanywhere家的,网址是:https://api.chatanywhere.tech, ...

网络的表示
在l2rpn环境中,节点或者说vertics被表示为母线,(bus/busbar),这个母线的定义是可以连接不同的电气元素的地方,需要注意的是母线不同于传输线,母线更多代表的是在一个站点内部的连接,类似于一个终端节点,可以连接电源、调相机、抑或是无功补偿设备。
其次,电力网络被抽象地表示为图(graph),图上的边则是连接两个母线的电力线。在grid2op中,不管是几回线,只要起点和终点相同,就被表示为一条线。
这个图可以使用grid2op.Observation.BaseObservation.get_energy_graph()
函数来表示,该函数返回一个networkx的图实例,也就意味着可以打印出来。
image-20240828172454572
可以看到这个图是一个networkx的Graph类
然后可以打印出来这个图的样子,但是首先使用自带的print看看是多少个节点和边:
image-20240828172617206
然后看看是什么样子,这里可以使用grid2op自带的打印函数PlotMatplot,可以从PlotGrid包中调用得到,在get ...

预告片啊,正片不要着急~~~
[{"url":"https://images.zhengxiaodong.com/beautybride.png","alt":"漂亮的新娘"},{"url":"https://images.zhengxiaodong.com/super.png","alt":"超级美女"},{"url":"https://images.zhengxiaodong.com/handsome.png","alt":"帅哥美女"},{"url":"https://images.zhengxiaodong.com/loveandsunset.png","alt":"夕阳之美"}]
加载更多


首先我们需要知道用于训练减小误差的均值方差公式: \[
\overline{\mathrm{VE}}(\mathbf{w}) \doteq \sum_{s \in \mathcal{S}}
\mu(s)\left[v_\pi(s)-\hat{v}(s, \mathbf{w})\right]^2
\]
其实在目前的研究中,均值方差未必是最好的目标函数,但是现在还没有找到其他更好的函数,且该目标函数是有效的,因此就一直连用了。
Episodic离散情况下的状态分布: \[
\mu(s)=\frac{\eta(s)}{\sum_{s^{\prime}} \eta\left(s^{\prime}\right)},
\quad \text { for all } s \in \mathcal{S}
\] 其中\(\eta\)
表示在每一个状态上的平均停留时间(步): \[
\eta(s)=h(s)+\sum_{\bar{s}} \eta(\bar{s}) \sum_a \pi(a \mid \bar{s}) p(s
\mid \bar{s}, a), \quad \text { for all ...
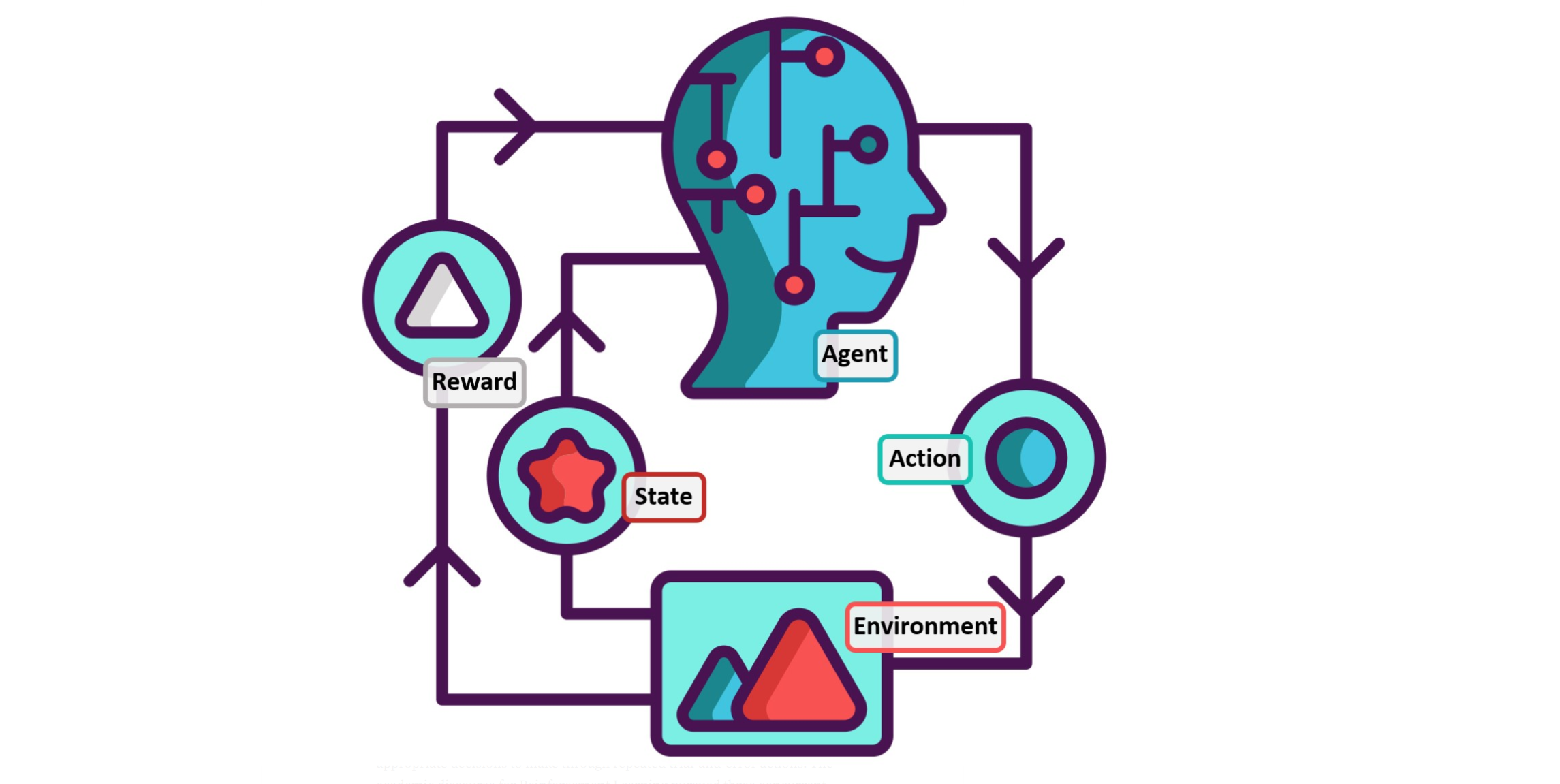
Lecture 4
Epsilon greedy
仔细想了想贪心算法,回顾一下并没有那么简单。贪心算法的定义是:
\[
\begin{equation}
\pi(a \mid s)= \begin{cases}a & \text { with probability }
\frac{\epsilon}{|A|} \\ \arg \max _a Q^\pi(s, a) & \text { with
probability } 1-\epsilon\end{cases}
\end{equation}
\]
也就是使用一个小的概率\(\epsilon\)来决定是探索还是深挖,即以\(\epsilon\)
的概率进行随机动作探索,从而获得那些潜在的可以带来更高未来回报的动作(当前一步不可见,但是在后续步骤中有可能拥有更多回报,也就是潜力更大),以1-\(\epsilon\)
的概率选择最大Q值的动作作为策略更新。
贪心算法是具有递增特性的,即如果对一个本身就是贪心算法进行贪心行为,那么可以得到其递增性,这里不容易想象到具体的案例,但是可以用公式表达:
\[
\begin{ali ...
Policy gradient的表示
A value function may still be used to learn the policy parameter, but
is not required for action selection. We use the notation \(\theta \in \mathbb{R}^{d^{\prime}}\) for
the policy's parameter vector. Thus we write \(\pi(a \mid s,
\boldsymbol{\theta})=\operatorname{Pr}\left\{A_t=a \mid S_t=s,
\boldsymbol{\theta}_t=\boldsymbol{\theta}\right\}\) for the
probability that action \(a\) is taken
at time \(t\) given that the
environment is in state \(s\) at time
\(t\) with paramet ...
TFT
开始合作,然后做对手在上一局地选择,即如果对手在上一局cooperate,那本局就cooperate,如果对手在上一局defect,那么就在本局defect。
Pavlov
如果两名玩家都在上局合作则本局合作,如果两名玩家都在上局背叛则本局选择背叛。
新的框架
policy generating function:
belief \(\beta_j\)
Influence function \(\theta\)
在想这三个指标是作者自己提出来的么?并没有在其他文章中见到过
Best response
多智能体学习最优反应
\[
B R_{i}(\hat{\theta})=\pi_{i}^{*}(s, a, \hat{\theta})=B
R_{i}\left(\boldsymbol{\pi}_{-i} \mid \pi_{j} \sim \beta_{j}\left(\tau
\mid h_{j}\right), h_{j} \sim p\left(h_{j} \mid h_{i}\right)\right)
\]
五种方式应对non-stationarity
行为
...

Lecture 3
Bias, Variance and MSE
偏差、方差、均方差
Consider a statistical model that is parameterized by \(\theta\) and that determines a probability
distribution over observed data \(P(x \mid
\theta)\)
Consider a statistic \(\hat{\theta}\) that provides an estimate of
\(\theta\) and is a function of
observed data \(x \quad
\hat{\theta}=f(x)\)
E.g. for a Gaussian distribution with known variance, the average of
a set of i.i.d data points is an estimate of the mean of the
Gaussian
Definition: the bias o ...

